Spark任务部署
Spark基本运行原理
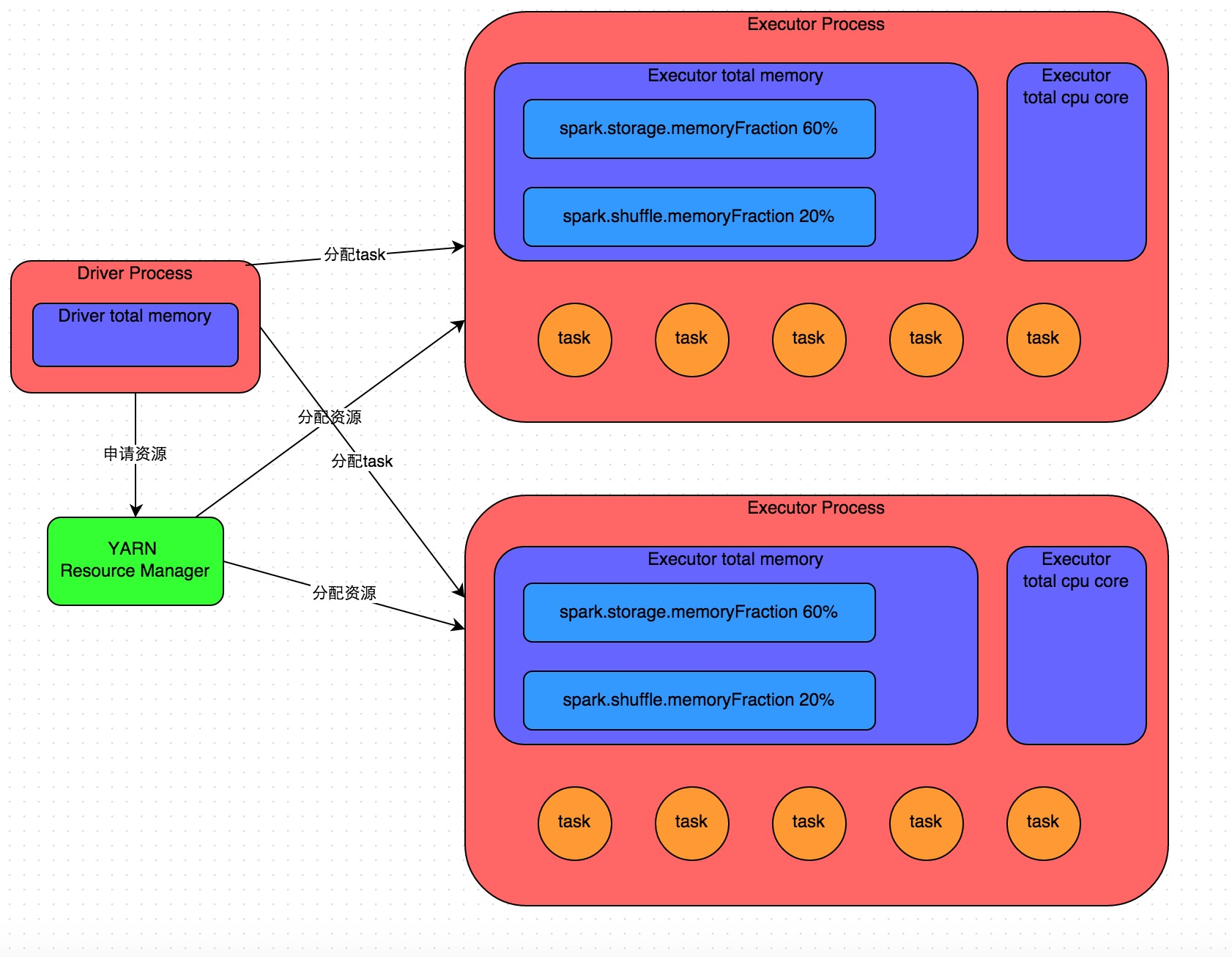
详细原理见上图。我们使用spark-submit提交一个Spark作业之后,这个作业就会启动一个对应的Driver进程。根据你使用的部署模式(deploy-mode)不同,Driver进程可能在本地启动,也可能在集群中某个工作节点上启动。Driver进程本身会根据我们设置的参数,占有一定数量的内存和CPU core。而Driver进程要做的第一件事情,就是向集群管理器(可以是Spark Standalone集群,也可以是其他的资源管理集群,美团•大众点评使用的是YARN作为资源管理集群)申请运行Spark作业需要使用的资源,这里的资源指的就是Executor进程。YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数量的Executor进程,每个Executor进程都占有一定数量的内存和CPU core。
在申请到了作业执行所需的资源之后,Driver进程就会开始调度和执行我们编写的作业代码了。Driver进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批task,然后将这些task分配到各个Executor进程中执行。task是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个task处理的数据不同而已。一个stage的所有task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的结果为止。
Spark是根据shuffle类算子来进行stage的划分。如果我们的代码中执行了某个shuffle类算子(比如reduceByKey、join等),那么就会在该算子处,划分出一个stage界限来。可以大致理解为,shuffle算子执行之前的代码会被划分为一个stage,shuffle算子执行以及之后的代码会被划分为下一个stage。因此一个stage刚开始执行的时候,它的每个task可能都会从上一个stage的task所在的节点,去通过网络传输拉取需要自己处理的所有key,然后对拉取到的所有相同的key使用我们自己编写的算子函数执行聚合操作(比如reduceByKey()算子接收的函数)。这个过程就是shuffle。
当我们在代码中执行了cache/persist等持久化操作时,根据我们选择的持久化级别的不同,每个task计算出来的数据也会保存到Executor进程的内存或者所在节点的磁盘文件中。
因此Executor的内存主要分为三块:第一块是让task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%;第三块是让RDD持久化时使用,默认占Executor总内存的60%。
task的执行速度是跟每个Executor进程的CPU core数量有直接关系的。一个CPU core同一时间只能执行一个线程。而每个Executor进程上分配到的多个task,都是以每个task一条线程的方式,多线程并发运行的。如果CPU core数量比较充足,而且分配到的task数量比较合理,那么通常来说,可以比较快速和高效地执行完这些task线程。
Spark作业提交
在分析spark运行模式前,首先理解下提交spark作业的spark-shell,和spark-submit: Spark-shell 是以一种交互式命令行方式将Spark应用程序跑在指定模式上,也可以通过Spark-submit提交指定运用程序,Spark-shell 底层调用的是Spark-submit,二者的使用参数一致的,通过- -help 查看具体参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
-master: 指定运行模式,spark://host:port, mesos://host:port, yarn, or local[n].
-deploy-mode: 指定将driver端运行在client 还是在cluster.
-class: 指定运行程序main方法类名,一般是应用程序的包名+类名
-name: 运用程序名称
-jars: 需要在driver端和executor端运行的jar,如mysql驱动包
-packages: maven管理的项目坐标GAV,多个以逗号分隔
-conf: 以key=value的形式传入sparkconf参数,所传入的参数必须是以spark.开头
-properties-file: 指定新的conf文件,默认使用spark-default.conf
-driver-memory:指定driver端运行内存,默认1G
-driver-cores:指定driver端cpu数量,默认1,仅在Standalone和Yarn的cluster模式下
-executor-memory:指定executor端的内存,默认1G
-total-executor-cores:所有executor使用的cores
-executor-cores: 每个executor使用的cores
-driver-class-path: driver端的classpath
-executor-class-path:executor端的classpath
其中spark配置文件的传入有三种方式:
1
2
3
1.通过在spark应用程序开发的时候用set()方法进行指定
2.通过在spark应用程序提交的时候用过以上参数指定,一般使用此种方式,因为使用较为灵活
3.通过配置spark-default.conf,spark-env.sh文件进行指定,此种方式较shell方式级别低
Spark作业运行模式
Spark 的运行模式有 Local(也称单节点模式),Standalone(集群模式),Spark on Yarn(运行在Yarn上),Mesos以及K8s等常用模式。
Local(单节点模式)
Local 模式是最简单的一种Spark运行方式,它采用单节点多线程(cpu)方式运行,local模式是一种OOTB(开箱即用)的方式,只需要在spark-env.sh导出JAVA_HOME,无需其他任何配置即可使用,因而常用于开发和学习
- 方式:./spark-shell - -master local[n] ,其中n代表线程数
Standalone(集群模式)
Spark可以通过部署与Yarn的架构类似的框架来提供自己的集群模式,该集群模式的架构设计与HDFS和Yarn大相径庭,都是由一个主节点多个从节点组成,在Spark 的Standalone模式中,主,即为master;从,即为worker.
- Standalone集群模式通过配置spark-env.sh和slaves文件来部署,可以通过以下配置:
1
2
3
4
5
6
7
8
9
vi spark-env.sh
SPARK_MASTER_HOST=192.168.137.200 ##配置Master节点
SPARK_WORKER_CORES=2 ##配置应用程序允许使用的核数(默认是所有的core)
SPARK_WORKER_MEMORY=2g ##配置应用程序允许使用的内存(默认是一个G)
vi slaves
192.168.137.200
192.168.137.201
192.168.137.202
- 启动集群:
sbin/start-all.sh
Spark on Yarn(运行在yarn)
Spark on Yarn 模式就是将Spark应用程序跑在Yarn集群之上,通过Yarn资源调度将executor启动在container中,从而完成driver端分发给executor的各个任务。 将Spark作业跑在Yarn上,首先需要启动Yarn集群,然后通过spark-shell或spark-submit的方式将作业提交到Yarn上运行。 spark on Yarn有两种模式,一种是client;一种为 cluster,可以通过- -deploy-mode 进行指定,也可以直接在 - -master 后面使用 yarn-client和yarn-cluster进行指定, 两种模式的区别在于:driver端启动在本地(client),还是在Yarn集群内部的AM中(cluster),rcs平台是采用双driver容灾的client模式,便于作业driver日志收集
- 提交作业之前需要将HADOOP_CONF_DIR或YARN_CONF_DIR配置到Spark-env.sh中:
1 2
vi spark-env.sh HADOOP_CONF_DIR=/opt/software/hadoop-2.6.0-cdh5.7.0/etc/hadoop
Client 模式:
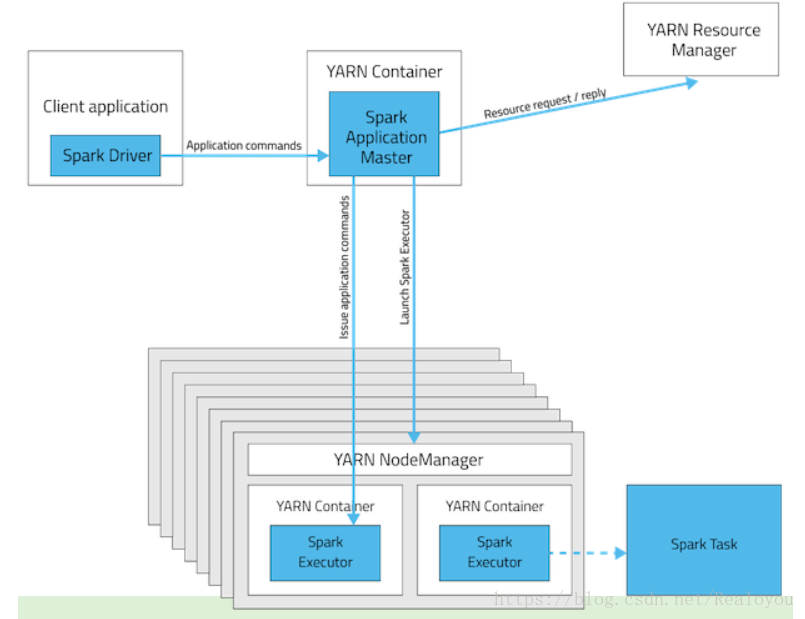
执行步骤如下:
-
Clinet模式下,客户端的Driver将应用提交给Yarn后,Yarn会先后启动ApplicationMaster和excutor,
-
ApplicationMaster和executor都装在在container里运行,container默认的内存是1g,
-
ApplicationMaster分配的内存是driver-memory,executor分配的内存是executor-memory.
-
同时,因为Driver在客户端,所以程序的运行结果可以在客户端显示,Driver以进程名为SparkSubmit的形式存在,提交作业的client就是driver。
Cluster 模式:
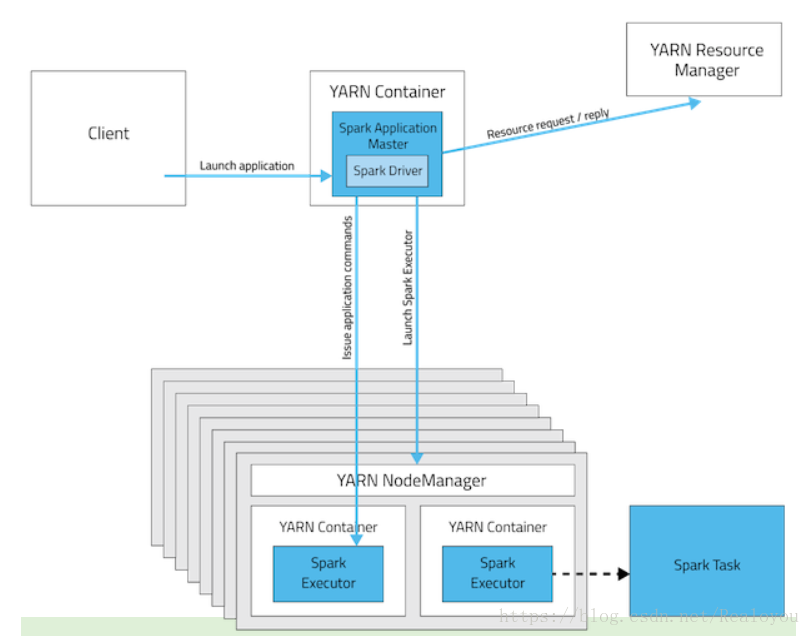
执行步骤如下:
- 先由client向Yarn 的 ResourceManager提交请求,并上传Jar到HDFS上
期间包括四个步骤:
1 2 3 4
a).连接到RM b).从RM ASM(applicationsManager)中获得metric,queue和resource等信息。 c).upload app jar and spark-assembly jar d).设置运行环境和container上下文
-
ResourceManager向NodeManager申请资源,创建Spark ApplicationMaster(每个SparkContext都有一个ApplicationManager)
-
NodeManager启动Spark App Master,并向ResourceManager ASM注册
-
Spark ApplicationMaster从HDFS中找到jar文件,启动DAGScheduler和YARN Cluster Scheduler
-
ResourceManager向ResourceManager ASM注册申请container资源(INFO YarnClientImpl: Submitted application)
-
ResourceManager通知NodeManager分配Container,这是可以收到来自ASM关于container的报告。(每个container的对应一个executor)
- Spark ApplicationMaster直接和container(executor)进行交互,完成这个分布式任务。